
Я публиковал эти заметки в Telegram канале по ходу чтения книги. Для легкости доступа и удобства поиска собрал их на одной странице. Нумерация соответствует выходу постов в канале.
1
Я пробовал читать эту книгу в оригинале в PDF, когда она только вышла, потом русский перевод тоже в PDF, но дальше первых страниц продвинуться не мог, не знаю почему, но электронный формат меня не устраивал.
Сейчас она появилась в библиотеке на работе, взяв её несколько дней назад и, читая только в метро два раза в день по 10-15 минут, я дошел до 100 страницы, что, на данный момент, наилучший результат.
Начнем с того, что в русской версии 580 страниц, 34 главы + приложения и куча отсылок, как к другим книгам O’Reilly, так и к сайтам в интернете. Добрые 30 страниц занимают предисловия и благодарности.
В отличие от The Phoenix Project, которая является художественным произведением, SRE скорее учебник, в котором теория сразу же объясняется на практике. Да и вообще вся книга это сборник статей от разных сотрудников Google, что, как я успел заметить, приводит к дублированию некоторых вещей в разных главах.
Вообще, послушав доклад SRE инженера из YouTube и начав читать книгу, думаешь о Google как о секте, в которой каждый как один говорит одно и то же.
2
“Надеяться - это плохая стратегия.”
Веб-сайты это не тоже самое что медицинское оборудование, между непосредственно твоим сервисом и пользователем существует много промежуточных звеньев, у которых надежность не 100%, поэтому пытаться создать веб-сервис с надежностью 100% не имеет смысла.
Как считает Google, DevOps все еще не вполне сформировался, а его основные принципы это привнесение IT-составляющей в каждую фазу создания систем (любых). DevOps можно рассматривать как обобщение некоторых основных принципов SRE для более широкого круга. А SRE, в свою очередь как конкретную реализацию DevOps со своей спецификой.
Работа SR-инженера делится на операционную и разработческую. Во-время первой они решают тикеты, реагируют на мониторинг и делают другую рутину. Во-время второй работают над улучшением сервиса, разрабатывая инструменты и автоматизируя все, что можно автоматизировать.
SR-инженеры, это в первую очередь разработчики. Рутина не должна превышать 50% времени их работы. Это строго мониторится и если такое происходит, то либо часть операционки передается SWE (разработчикам), либо разработчики добавляются в команду SRE, но без операционной нагрузки.
3
Каждый продукт должен иметь установленный целевой показатель доступности. Это не полностью технический вопрос, он должен определяться в диалоге с бизнесом. Допустим, мы установим целевой показатель доступности в 99,99%, тогда 100% - 99,99% = 0,01% допустимый уровень недоступности сервиса или бюджет ошибок.
Бюджет потому что его можно и нужно тратить. Целевой показатель доступности и бюджет ошибок, должны формироваться как для сервисов с которыми взаимодействуют пользователи, так и для инфраструктурных сервисов, клиентами которых являются внутренние приложения.
На практике, для поддержания общего уровня надежности на определенном уровне, надежность инфраструктурных сервисов должна быть всегда выше чем надежность приложений с которыми взаимодействуют пользователи.
4
Бюджет ошибок расходуется как SWE так и SRE. На ошибки во-время или после деплоев, т.е. на новые фичи, на отказ любого оборудования/инфра сервисов и т.д. Даже если сервис слишком стабильный, бюджет ошибок необходимо расходовать принудительно.
Пример из опыта Google: инфра сервис Chubby (аналог ETCD) используемый для блокировок, работал без сбоев, и разработчики привыкли, что он не падает. Когда он наконец-то упал, сервисы жестко на него завязанные, были полностью недоступны. Выяснилось, что разработчики на столько привыкли к его стабильности, что не задумывались о ретраях и реконнектах.
С тех пор, в Chubby искусственно создают недоступность, чтобы держать в тонусе разработчиков. Бюджет ошибок высчитывается для квартала или месяца, и если до конца этого периода, он потрачен, то выпуск новых фич приостанавливается и ресурсы перенаправляются на усиление надежности проекта.
5
Занимаясь операционными задачами, каждый SR-инженер, как правило, получает не более двух событий за 8-12 часовую смену. Такой объем работы дает возможность быстро и точно обработать событие. Больше - выгорание, меньше - зачем тогда SRE вообще нужно этим заниматься?
Надежность проекта и скорость внедрения изменений находятся на противоположных чашах весов, хотим больше надежности, будет меньше фич и наоборот. Интересы разрабов - новые фичи, интересы опсов - надежность, конфликт разруливается через бюджет ошибок. Обе команды стремятся расходовать предоставленный бюджет ошибок так, чтобы максимально быстро внедрить новый функционал и выпустить продукт.
Сбои и баги, не считаются чем-то плохим - это ожидаемая часть внедрения изменений, команды не боятся их а управляют ими.
6
“Система мониторинга никогда не должна требовать от человека истолковывать какую либо часть оповещения.”
3 категории данных от системы мониторинга: срочные оповещения (алерты), запросы на действия (тикеты), журналирование (логи).
Надежность это функция от среднего времени безотказной работы (mean time to failure, MTTF) и среднего времени восстановления (mean time to repair, MTTR).
Три приема чтобы эффективно ограничивать общее количество сбоев:
- обеспечить поэтапное развертывание обновлений
- быстро и точно выявлять проблемы
- безопасно откатывать изменения при проблемах
7
Из интересного про железо гугла.
Все дата-центры устроены одинаково. Машины не выделяются под конкретные задачи, они все вводятся в кластер Borg (Kubernetes), который уже решает где что запустить.
Для поддержки высокой пропускной способности сети между машинами внутри ДЦ, Google использует собственные свитчи, которые управляются виртуальным коммутатором. Все это дело называется Jupiter (1,3 Пб/c) и построено на топологии Клоза.
Дата-центры соединены между собой по OpenFlow c помощью глобальной магистральной сети B4.
Для роутинга используются глупые коммутаторы в сочетании с центральным контроллером, который заранее вычисляет лучший маршрут сети.
Bandwidth Enforcer (BwE) управляет доступной полосой пропускания, а Global Software Load Balancer, GSLB выполняет балансировку на трех уровнях:
- географическую для DNS-запросов
- балансировку на уровне пользовательских сервисов (YouTube, Google Maps и т.д.)
- балансировку нагрузки на уровне RPC
8
Архитектура Borg это прям K8s, а вот файловое хранилище заинтересовало.
Если я правильно понял, диски всех машин, объединены в одну большую файловую систему (Colossus) и её используют разные storage провайдеры - Bigtable петабайтный NoSQL, Spanner SQL-подобный интерфейс или простой Blobstore.
Задачи, запускаемые c помощью Borg, делятся на одноразовые (типа mapReduce, но их может быть очень много) и серверы (т.е. работающие в лупе).
Глобальный сервис Chubby используется для блокировок (выбор мастера например или лок задачи).
Все сервисы общаются с помощью инфраструктуры RPC, которая называется Stubby (gRPC), внутри protobuf.
Весь код, всех проектов лежит в едином репозитории (ОН ГИГАНТСКИЙ).
9
Все сервисы на каждый запрос ломятся в Global Software Load Balancer. DNS сервер идет в балансер, чтобы знать в какой прокси сервер отправлять, тот в свою очередь чтобы узнать в какое фронтенд приложение, которое в свою очередь идет опять в балансер чтобы знать где бекенд и т.д.
Количество запущенных задач (инстансев приложения) должно быть N+2, во время обновления одна будет в дауне, а одна может упасть, тогда останется N - что есть минимум для обработки пиковой нагрузки.
10
В классическом случае, доступность рассчитывается по формуле:
Доступность = время безотказной работы / время безотказной работы + время отключений
Т.е. для требуемой доступности 99,99, время возможных отключений будет 52,56 минут, если брать период год.
Google не очень нравится использовать такой расчет доступности. Для их задач больше подходит доля успешных запросов в рамках одного дня. Формула расчета:
Доступность = успешные запросы / все запросы
Если в день 2,5 миллиона запросов и требуемая доступность 99,99, допустимо терять из-за сбоев 250 запросов.
Определение времени незапланированных отключений таким образом, позволяет также использовать его для систем которые не обслуживают конечных пользователей.
Уровень доступности устанавливается для квартала, а отслеживается еженедельно или ежедневно.
Заметка между заметками
Неважно каким способом мы измеряем доступность сервиса, обозначать её принято в процентах. Максимальная доступность любого сервиса 100%.
Требуемая доступность у всех сервисов разная, но зачастую это что-то вроде 99,99% или 99,999%.
Так как произносить это слишком долго и непонятно. Мы говорим просто 4 девятки или 5 девяток и т.д.
11
Стоимость cистемы при повышении надёжности растет нелинейно - след. шаг повышения надёжности может стоить в 100 раз больше предыдущего. Две составляющие этой стоимости:
- Стоимость избыточных вычислительных ресурсов
- Cтоимость упущенных возможностей (инженеры не пилят фичи)
Покрывает ли дополнительная прибыль затраты на достижение нового уровня надёжности ?
Что лучше для сервиса постоянные короткие сбои или редкие но долгие?
12
Понятия успешного функционирования системы и её отказа для разных групп пользователей/сервисов могут быть разными.
Например, кому-то важно чтобы очередь задач всегда была полная и воркеры не простаивали, а кому-то наоборот, нужно чтобы воркеры были свободны и как только задача попала в очередь она как можно быстрее была обработана.
Менеджер продукта определяет SLO, задавая тем самым время бесперебойной работы в течение квартала
Реальное текущее время бесперебойной работы измеряется нейтральной стороной - системой мониторинга.
Разница между этими числами является запасом (бюджетом).
Пока доля времени бесперебойной работы больше времени, заданного SLO, можно продолжать выпуск новых версий и изменения.
13
Сегодня начинается очень интересная для меня тема - SLI/SLO/SLA. В книге они достаточно детально формализованы и показаны на примерах.
SLI, Service Level Indicators - показатели (индикаторы) уровня качества обслуживания.
SLO, Service Level Objectives - целевые показатели. Целевые уровни качества обслуживания.
SLA, Service Level Agreements - соглашения.
14
SLI - четко определенное числовое значение конкретной характеристики. Чаще всего это:
- время отклика или латентность системы, ms
- уровень или частота ошибок, % от общего числа запросов
- пропускная способность системы, RPS/QPS
- доступность - доля времени когда сервис можно использовать
15
SLO - целевое значение или диапазон значений, измеряемые с помощью SLI.
SLI ≤ целевое значение
нижняя граница ≤ SLI ≤ верхняя граница.
Как я понял что такое SLO: допустим, мы установили SLI - процент 5xx ошибок, SLO будет - процент 5xx ошибок не должен превышать значение в 2%.
Для SLO стоит уточнять измеряемый период (окно).
16
SLA - явный или неявный контракт с вашими пользователями, включающий последствия, которые влечет за собой соответствие (или несоответствие) требованиям SLO.
Простой способ понять разницу между SLO и SLA, ответить на вопрос: что случится, если требования SLO не соблюдаются?
Если явных последствий не существует, то, скорее всего, перед вами SLO.
SLA относится к бизнесу, в то время как SRE инженеры занимаются SLI и SLO.
17
Работать с перцентилями лучше чем со средним арифметическим. Среднее арифметическое и медиана, обычно имеют разные профили.
SLO должны содержать информацию о том, как их измерять, а также условия, при которых они действительны. Пример:
99% вызовов RPC Get будут завершены менее чем за 100 милисекунд
Суммарный уровень ошибок - это SLO, отражающий соответствие другим SLO!
По SLO должен вестись ежемесячный или ежеквартальный отчет.
18
Советы по выбору SLO:
- не выбирайте цель, основываясь на текущей производительности
- не усложняйте
- не гонитесь за абсолютом
- имейте минимальное количество SLO
- идеал может подождать
Хорошо построенные SLO - полезный фактор воздействия на команду.
Плохо продуманные SLO, могут привести к пустой трате рабочего времени.
19
Чтобы ожидания пользователей были реалистичными, нужно использовать тактики:
- имейте запас прочности (внутренние SLO жестче, чем внешние)
- избегайте перевыполнения (история с Chubby)
Чем шире будет круг ваших пользователей, тем сложнее будет изменить/удалить необоснованные или трудновыполнимые SLA.
20
Пожалуй пропущу заметки по скучной организационной теме и перейду к мониторингу.
Что входит в мониторинг:
- Мониторинг белым ящиком
- Мониторинг черным ящиком
- Дашборды
- Алерты (тикеты и вызовы)
Что дает мониторинг: - Анализ долгосрочных тенденций - Сравнение метрик в экспериментах - Оповещение - Дашборды - Ретроспективный анализ
Observability man - человек ответственный за мониторинг, алерты и дашборды.
Алерт должен давать ответ на два вопроса:
- Что сломалось? - симптом
- Почему? - причина
21
4 золотых сигнала - если вы можете измерить для системы только 4 показателя, сконцентрируйтесь на этих:
- время отклика. задержка для успешных и неуспешных запросов
- величина трафика. для веб-сервиса - количество HTTP запросов в секунду, для системы потокового аудио/видео - скорость/объем передачи данных по сети или количество параллельных сессий, для K/V стораджа - количество выполненных транзакций и возвращенных значений за секунду и т.д.
- уровень ошибок. error код, успешный код но с пустым результатом и успешный код но недостаточно быстро это все ошибки
- степень загруженности - CPU, Memory, IO, Network. Многие системы теряют в производительности еще до того, как будут загружены на 100%
Если вы можете измерить все четыре сигнала и сообщать пользователю если один из них обнаруживает проблему, ваш мониторинг можно считать удовлетворительным.
22
Ну и последнее, на данный момент, по теме мониторинга.
- Измерение 99-го перцентиля времени отклика в минуту - предупреждение о перегрузке.
- Важно иметь прогнозы достижения целевого уровня, например, “База заполнит диск через 12 часов”.
- Гистограммы должны строиться с логарифмическими границами. Например время ответа от 0 до 10, от 10 до 30, от 30 до 100, от 100 до 300 и т.д.
- Усреднение (average) может быть принятием желаемого за действительное, нужно использовать медианы и перцентили.
- Правила, которые определяют аварии, должны быть максимально простыми, предсказуемыми и надежными.
- Избавьтесь от частей системы мониторинга, которые используются редко.
- Показатели, которые система не выводит и не использует в алертах - кандидаты на удаление.
23
Прохладная история про автоматизацию.
Google управляет ресурсами на уровне стоек (в одной стойке могут быть десятки серверов), и процесс ввода новых и вывода ненужных полностью автоматизирован.
Один из этапов выведения стойки серверов, очистка дисков путем забивания бесполезным хламом. Так вот, как то раз, автоматическое выведение стойки прервалось сразу после этого этапа, а потом запустилось заново.
Но на этот раз сценарий получил пустой список серверов для работы (так как они уже были очищены) и решил (ВНИМАНИЕ!) что нужно обработать все серверы в этом ДЦ.
Это были серверы CDN, т.е. там хранился только кэш, чтобы пользователи из ближайших регионов быстрее получали данные. Все серверы были потеряны, но благодаря достаточно надежной инфраструктуре, это отразилось только лишь небольшим увеличением времени ответа для некоторых пользователей.
Восстанавливали серверы несколько дней, а потом еще две недели искали и исправляли ошибку. Но в большинстве случаев автоматизация все таки полезная штука, даже если размер вашей компании не уровня Google.
24
Я прочитал главу “Выпуск ПО”. Не знаю, может быть тема CI/CD, при всей её простоте, уже слишком заезжена, а может быть уже все это знаю, но глава показалась скучной.
Если говорить в двух словах, то у них там куча самописного ПО, для сборки и доставки, но пару заметок я все таки запишу.
К их монорепозиторию подключен CI, который билдит все теги (веток там нет), а дальше работает CD.
4 основных принципа CD от гугла:
- Самообслуживание
- Скорость
- Герметичные сборки
- Политики и процедуры контроля доступа
Любят они, по ходу, цифру 4
25
- Rapid - система управления релизами
- Blaze (Bazel) - сборка
- Midas - менеджер пакетов (собранные пакеты называются MPM пакеты)
- Sisyphus - универсальный фреймворк для автоматизации
Флоу получается примерно такой:
Система непрерывного тестирования (CI) -> Rapid (Pipeline) -> Blaze (сборка артефактов) -> Artefact -> Midas/Sisyphis (деплой)
Деплой на прод, естественно, Canary, т.е. потихоньку, сначала на малый процент пользователей, потом больше, еще больше и так далее.
26
Sisyphus - предоставляет набор классов Python, который может быть расширен для поддержки любого процесса развертывания и установки.
Несколько моделей для распространения файлов конфигурации. Все схемы включают хранение конфигураций в основном репозитории исходного кода.
- конфиги в репозитории - релиз кода отдельно, изменение конфигов отдельно
- включение конфигов в MPM пакет с бинарем - релиз конфигов вместе с исполняемым кодом
- сборка конфигов в отдельные конфигурационные пакеты MPM - независимый релиз кода и конфигов, но можно создать зависимость
- конфиги во внешнем хранилище (Chubby, Bigtable или файловой системе Kemper)
Владельцы проекта могут использовать разные варианты распространениея и управления конфигами, в зависимости от ситуации и потребностей.
27
II часть книги - “Принципы”, заканчивается главой “Простота”, таким себе набором цитат и капитанских фраз.
Сложные системы (ПО в частности) по своей природе динамичны и нестабильны.
SR-инженеры стараются создавать надежные инструменты, гарантируя что их работа будет минимально влиять на гибкость разработчиков. Таким образом их работа, это соблюдать баланс между надежностью и гибкость.
“В отличие от детективной истории, желательно, чтобы исходный код не давал повода для волнения, беспокойства и загадок”
Роберт Мут, инженер Google
Существует органичная (естественная) и неорганичная (случайная) сложность. Первая возникает в силу необходимости и с ней ничего нельзя сделать, а от второй нужно избавляться. Трюк в том, чтобы понять, что перед тобой неорганическая сложность.
28
Поддерживая веб-сервис c доступностью 24/7 вы несете ответственность за каждую новую строку кода. Нужно гарантировать что весь код следует исходной цели. Можно использовать следующий приемы:
- анализ кода
- удаление “мертвого” кода
- автоматическое обнаружение “разбухания” кода
Минимальные API - чем меньше методов и аргументов в API, тем проще с ним работать
Модульность - одно API не обязательно должно состоять из одного исходного файла (сервиса), иначе со временем это будет “солянка”.
Простые релизы - чем меньше изменений в релизе, тем легче определить что привело к проблемам, более быстрые тестирование и деплой и т.д.
Проще - надежнее
29
Начинается тема про дежурства или как говорят в гугле “пейджер”
Пусть запросы идут а ваш пейджер молчит (May the queries flow, and the pager stay silent)
- благословение SR-инженеров
Prometheus очень похож на Borgmon - что не удивительно, так как он был вдохновлен гугловым мониторингом.
И Prometheus и Borgmon, работают быстро, пока метрики хранятся в памяти, поэтому гугл использует каскадную модель.
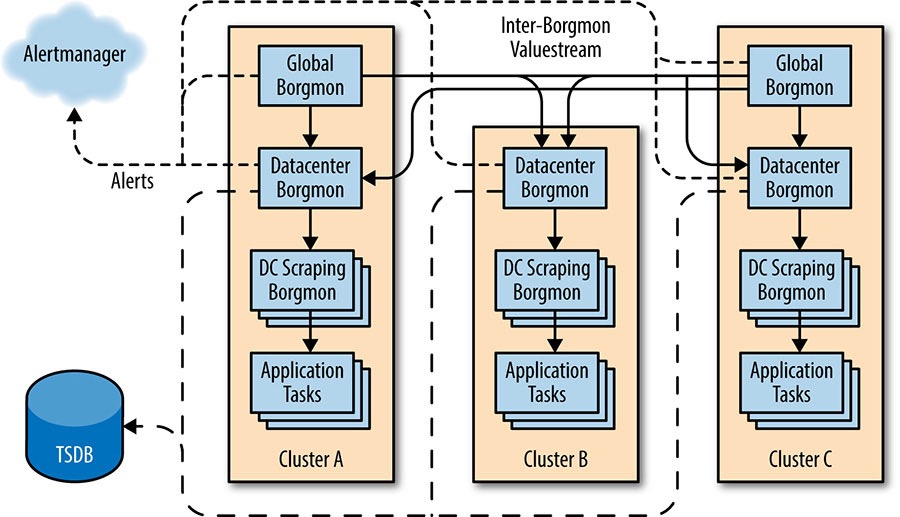
Самый первый Borgmon держит метрики за 12 часов, и это примерно 17 Гб в памяти. Данные старее 12 часов перекладываются в другой Borgmon а из него в третий и в итоге в TSDB. Собственно Prometheus предлагает такое же решение для долгосрочного хранения.
Знаю что в крупных русских компаниях, типа Avito и Mail.ru, перекладывают метрики в другие стораджи, такие как Graphite.
Также у гугла есть unit и регрессионные тесты для конфигурации Borgmon, перед применением к проду.
30
С тех пор как речь пошла о дежурстве и мониторинге в книге постоянно упоминается система временных рядов для хранения метрик и я не сразу вкурил что “Питер” так перевел time-series database. Но вернемся к заметкам поважнее.
В пейджере всегда есть приоритетность:
- самое критичное - сразу дежурному
- важное, но не критичное - дежурному, но через тикет
- все остальное - просто на монитор
Существуют первая и вторая очереди дежурств. Есть разные варианты организации: либо первая решает ASAP’ы, вторая тикеты (сплит по типам), либо если первая не справилась за какое-то время, то передается второй (эскалация по времени).
Работа SRE состоит из разных частей:
- 25% дежурство
- 25% другая работа (джиринг, митинги, написание отчетов и документации и т.д.)
- 50% инжиниринга
Сохранять эти проценты очень важно. Дежурство и рутина наносят определенный урон инженеру, в книге просто упоминаются гормоны кортизол и КРГ, поэтому я поискал немного информации и вот пара цитат.
Если единичное повышение уровня кортизола из-за неожиданного голода или чрезвычайно активных физических нагрузок «всего лишь» разрушает мышцы, то постоянно высокий уровень этого гормона приводит не только к хроническому стрессу и усилению раздражительности, но и ведет к существенному ухудшению метаболизма и обмена веществ. Научные исследования показывают, что хронически высокий уровень кортизола вызывает как общий набор висцерального жира, так и усиленное отложение жировой клетчатки в проблемных местах (у мужчин на боках, внизу живота и спины, у женщин — на бедрах). Высокий кортизол провоцирует ожирение, а ожирение — дальнейшее повышение уровня кортизола, создавая таким образом замкнутый круг.
В целом действие КРГ на ЦНС сводится к усилению реакций активации, ориентировки, к возникновению тревоги, страха, беспокойства, напряжения, ухудшению аппетита, сна и половой активности. При кратковременном воздействии повышенные концентрации КРГ мобилизуют организм на борьбу со стрессом. Длительное воздействие повышенных концентраций КРГ приводит к развитию состояния дистресса — депрессивного состояния, бессонницы, хронической тревоги, истощению, понижению либидо.
31
Важнейшие ресурсы для дежурного :
- хороший менеджмент
- процедуры обработки инцидентов
- безобвинительная культура написания отчётов
Если процедуры обработки инцидентов зафиксированы в специальных протоколах (базе знаний, например), работа дежурного облегчается, Time To Recover снижается, меньше стресса у дежурного, больше стабильности сервиса.
Эвристика соблазнительное зло. Например: сервис перестал отвечать на запросы, на прошлой неделе было такое же поведение из-за перегрузки CPU, значит и в этот раз тоже самое.
Если приложение стало “шуметь” SRE команда может передать пейджер SWE команде, до момента пока они с этим не разберутся.
Если операционной работы нет, надо проводить учения. Например, “Колесо не удачи” о котором, видимо, будет рассказано позднее.
Стресс-тест для всей компании “DiRT - disaster recovery training”
32
Для диагностики и решения проблем стоит применять гипотетико-дедуктивный метод.
- изучить отчет об ошибке, проверить результаты телеметрии и логи
- зная как построена система и как она реагирует на ошибки выдвинуть предположение
- проверить предположение, если не помогло, вернуться на шаг 1
Могут быть подводные камни:
- мартышкин труд - изучение симптомов, которые не относятся к делу или дают неверную информацию о состоянии системы
- отсутствие понимания что и как можно изменить в системе
- самые невероятные предположения или наоборот “надежда что это тоже что и в прошлый раз”
- поиск кажущихся зависимостей
Пилотов учат, что в случае ЧП они все равно должны пилотировать самолёт, поиск проблемы вторичен, по сравнению с тем, что нужно безопасно посадить самолёт на землю.
33
Что-то я задержался с SRETuesday, и публикую его в среду. Продолжаем говорить про пейджер и приближаемся к тому, что делать во время аварии
В идеальном случае, авария начинается с отчета об ошибке (по простому алерта), а идеальный отчет об ошибке содержит в себе следующую информацию:
- ожидаемое поведение
- реальное поведение
- способ воспроизведения
Для расследования аварии можно использовать следующие инструменты:
- мониторинг
- трассировка запросов
- журналы
Как уже было сказано, для мониторинга Google использует Borgmon (Prometheus). Для трассировки запросов Dapper.
Журналы (логи) - это текстовые, пригодные для чтения человеком данные системы. И относительно логов, Google дает следующие рекомендации:
- полезно иметь несколько уровней их детализации и возможность повышать или понижать уровень по мере надобности, на лету, не нарушая работу сервиса
- должны позволять изучить любую операцию без перезапуска процесса
- в зависимости от объема трафика, может быть полезно использовать “прореженную” выборку логов, например протоколировать не все, а каждую тысячную операцию
34
Итак, что-то я совсем забыл про #SRETuesday, а вы меня и не пинаете. Продолжаем про дежурство и диагностирование проблем.
Упрощайте и сокращайте (декомпозируйте систему)
Как диагностировать сложную многосвязную систему? Есть два варианта:
- двигаться по цепочке с одного конца к другому, например:
от клиента к балансировщику, от балансировщика к веб-серверу, от веб-сервера к бекенду, от бекенда к базе и т.д. но это может быть слишком долго - делить цепочку пополам, проверять какая половина не работает и делить уже её пополам и повторять пока не найдешь неработающий компонент
Что, где и почему
Сбоящая система все еще пытается работать и что-то делает, но не то что нужно. Нужно выяснить ЧТО именно она делает, ПОЧЕМУ это происходит, ГДЕ расходуются ее ресурсы и КУДА направляются результаты. Все это может помочь в понимании что пошло не так.
Тут книга отсылает нас к 5 почему Таичи Оно
Какое воздействие было последним?
У систем есть инерция: Google выяснили что неподверженная внешним воздействиям компьютерная система имеет тенденцию продолжать работать, например, пока не изменится конфигурация или тип нагрузки.
Недавние изменения в системе отличное место к расследованию того, что пошло не так. Хорошей отправной точной для изучения проблемы будет анализ последних изменений в системе.
Детализация и логирование изменений и взаимодействий
Легче всего диагностировать систему в которой есть качественное логирование изменений и взаимодействий, причем должна быть возможность легко узнать детали, чтобы подтвердить или опровергнуть что данное изменение или взаимодействие привело к проблемам.
35
Жизнь так устроена, что всё когда нибудь ломается
Время и опыт показывают, что системы не просто ломаются, а ломаются так, как никто не мог представить. Порою, решение может лежать дальше чем может видеть дежурный, особенно с разрывающимся пейджером.
Задействуйте больше людей, делайте то, что считаете нужным, но делайте это быстро. Главное быстро взять ситуацию под контроль.
Тот кто причастен к возникновению ситуации, больше всех о ней знает, найдите его, а после восстановления напишите отчет.
Для подтверждения диагноза:
- результаты тестов должны быть взаимоисключающими
- проверяйте в первую очередь очевидные вещи
- результаты эксперимента могут ввести в заблуждение (порт открыт для IP, коннект к базе с локали не прокатит)
- активное тестирование может привести к побочным эффектам
- результаты некоторых тестов бывают слишком ненадежны, чтобы однозначно на них полагаться
Как облегчить решение проблем?
- максимум наблюдаемости (observability) - белый ящик, логи и т.д.
- разрабатывайте системы с предельно понятными и наблюдаемыми интерфейсами между компонентами
- храните историю перебоев в работе с шагами исправления, убедитесь что у всех есть к ним доступ
- постоянно задавайтесь вопросом “а что если?” (например: а что если редис упадет?)
Отрицательный результат важен!
Например: одна команда протестировала библиотеку и выяснила что у нее есть недостатки, зная это, другая команда может не тестировать данную библиотеку, а сразу использовать другую.
36
Чтобы успешно справляться с авариями, в Google разработали свою систему управления в критических ситуациях, основанную на системе управления инцидентами (Incident Command System, ICS). Вот основные моменты этой системы:
Рекурсивное разделение обязанностей - каждый занимается своим делом и не заходит на чужую территорию. Если нагрузка на одного слишком большая, нужно запросить больше исполнителей (ДЕЛЕГИРУЙ!)
Роли работающих над инцидентом:
- управление - начальник штаба, контролирует весь процесс, распределяет обязанности, выполняет нераспределенные, устраняет препятствия мешающие оперативной группе.
- оперативная группа - непосредственно устраняют инцидент, только они могут вносить изменения, лидер оперативной группы, если такой есть/необходим, общается с начальником штаба
- информирование - лицо всей команды. Задача - держать в курсе происходящего всех.
- планирование - регистрация найденных ошибок, заказ обеда, планирование и организация передачи задач между исполнителями, отслеживание и фиксация аномалий в системе, чтобы исправить после разрешения инцидента
Выделенный центр управления - по возможности всех нужно собрать в одном месте. IRC помогает координировать и фиксировать события.
Обновляемый документ о состоянии инцидента - начальник штаба должен вести документ об инциденте, в гугле все используют Google Docs, но сама команда SRE Docs использует Sites.
https://landing.google.com/sre/sre-book/chapters/incident-document/
Четкая и оперативная передача полномочий
→ сейчас ты управляешь инцидентом, понятно?
… остается на связи
→ да
может быть свободен
Лучше объявить об инциденте как можно раньше, найти простое решение и закрыть инцидент, чем часами развертывать штаб в условиях ухудшения проблемы.
Определите четкие условия для объявления инцидента. Например:
- необходимо привлечь вторую команду, чтобы решить проблему
- перебой в работе заметили клиенты
- проблема не решена после нескольких часов работы
37
Практические рекомендации по управлению инцидентом
Расставляйте приоритеты - остановите развитие аварии, возобновите работу сервиса и сохраните данные для анализа истинных причин аварии
Готовьтесь заранее - разрабатывайте и документируйте методы управления инцидентами, согласовывая их со всеми участниками
Доверяйте - полная самостоятельность в рамках отведенных ролей
Используйте самоанализ - если паникуешь или перегружен запроси помощи
Рассматривайте альтернативы - пересмотр приоритетов задач
Практикуйтесь - применяйте подходы по управлению инцидентами постоянно, чтобы это вошло в привычку
Проводите ротацию - стимулируйте всех участников команды ознакомиться с каждой ролью.
38
Культура постмортема, учимся на ошибках
Ошибки - плата за знания.
- Девин Кэрреуэй
Концепция “разбора полетов” и так называемого постмортема хорошо известна в индустрии высоких технологий.
Постмортем представляет собой письменный отчет об инциденте, его последствиях, действиях, предпринятых для его смягчения или устранения, его первопричине (или первопричинах), а также о последующих действиях для предотвращения его повторения.
Проведение “разбора полетов” и составления постмортема ожидается после любого значительного нежелательного события.
Это не наказание, а возможность научиться чему-то новому для всей компании.
Команды сами решают когда писать постмортем, но есть ситуация когда он необходим:
- обнаруженное пользователями время простоя или ухудшение производительности ниже определенного порога
- потеря данных любого типа
- потребовалось вмешательство дежурного инженера (откат изменений, перенаправление трафика)
- время разрешения ситуации превысило определенный лимит
- ошибка системы мониторинга (обнаружение инцидента пользователем или инженером)
Критерии составления посмотрем должны быть определены до возникновения инцидента, чтобы каждый понимал их, но также любая заинтересованная сторона может его затребовать для конкретного события.
Безобвинительный “разбор полетов” является краеугольным принципом для всей службы SRE. Эта культура берет начало в здравоохранении и авиации, где ценой ошибки может стать чья-то жизнь.
Нельзя “исправить” людей, зато можно исправить системы и процессы.
Тыканье пальцем: “бэкенд отстой, выходит из строя каждую неделю, если меня вызовут еще хотя бы раз, перепишу его сам”
Безобвинительный тон: “изменение бэкенда может предотвратить дальнейшее возникновение подобных ситуаций, будущие инженеры скажут вам спасибо”
Избегайте обвинений и будьте конструктивными.
39
Продолжаем про постмортем, важное:
- шаблоны постмортем
- ведение всех постмортем в одной системе
- открытая система для комментариев
- уведомления
Оценка постмортем:
- собраны ли ключевые данные по инциденту для последующего исследования?
- является ли оценка влияния полной и завершенной?
- была ли найдена основная причина?
- целесообразны ли план действия и очередность последующих исправлений ошибок?
- поставлены ли заинтересованные стороны в известность о результатах?
Семинары для разбора постмортем - доводить до завершения дискусии, фиксировать идеи и придавать окончательный вид документам. Когда все довольны в архив его.
Etsy выложили свою систему для хранения постмортем - Morgue.
Для воспитания культуры постмортемов:
- постмортем месяца - в рассылке распространяется наиболее содержательный и качественный постмортем
- группа Google+ посвященная постмортем
- книжные клубы по постмортемам - регулярные собрания, за освежающими напитками рассматриваются особенно интересные или значимые и ведется открытый диалог
- “колесо неудачи” - ролевая игра, в ходе которой разыгрываются события какого-либо постмортема. Новые SR инженеры часто проходят через это упражнение.
40
Явно вознаграждайте людей за правильные поступки (история)
Основатели Google Ларри Пейдж и Сергей Брин проводят TGIF (Thank God It’s Friday)- еженедельные собрания сотрудников в прямом эфире с трансляцией в офисы Google по всему миру.
Одно из TGIF 2014 было посвящено теме “Искусство постмортема” и включало дискуссию SR-инженеров о событиях с серьезными последствиями.
Один из них залил обновление, которое вывело из строя важнейший сервис. Инцидент продолжался 4 минуты, потому что инженер не растерялся и немедленно откатил изменения. Этот инженер не только немедленно получил два партнерских бонуса в награду за быстрые и грамотные действия по разрешению инцидента, но и сорвал шквал аплодисментов на пятничном мероприятии, включая основателей и многотысячную аудиторию.
Глава про постмортем заканчивается, остается записать только, что в Google есть отдельная группа которая занимается посмортемами - улучшают шаблоны, помогают внедрить культуру и т.д. И буквально последнее предложение:
Дальнейшая работа в этой области предполагает внедрение технологий машинного обучения, которое сможет заранее сообщить о слабых местах, облегчить исследование инцидентов в реальном времени, а также сократить количество дублирующих инцидентов.
41
Интересная штука в главе “Контроль неисправностей”
В Google сделали сервис, в который попадают копии всех алертов SR-инженеров. А затем, научили её проверять получил ли уведомление инженер и если нет, то отправлять оповещение по цепочке выше, и назвали эту систему Escalator. (Мы для этого используем VictorOps)
Затем они пошли еще дальше и сделали Outalator - штуку, в которую сваливаются все уведомления, где их можно группировать (в инцидент), промаркировать, смотреть по всем командам в одном месте и, например, прикрепить к письму при передаче дел, ну и конечно они там лежат как в архиве и в случае чего к ним можно обратиться, для анализа.
Плюсы Outalator’а:
- возможность определить что оповещения связаны с другим, уже известным сбоем (ускоряется диагностика, снижается нагрузка на другие команды)
- мониторинг количества инцидентов и фона алертов в разных командах и сервисах (помогает в принятии решений)
- “режим отчета” для периодических (обычно раз в неделю) проверок сервисов в эксплуатации
- можно увидеть, что команда, которую необходимо уведомить не была проинформирована и сделать это вручную
P.S. кстати недавно Monzo (UK-based банк нового поколения) заопенсорсили тулзу для управления инцидентами завязанную на Slack
42
Тестирование - глава довольно скучная, пролистал по диагонали.
Google пишет, что у них следующие виды тестирования:
- модульное (unit)
- интеграционное
- системное
Системное в свою очередь делится на:
- смоки - простые быстрые, показывающие что система работает
- перфоманс - что производительность не падает со временем
- регресссы - что ошибки которые были в прошлом не вылезут в будущем
Помимо этого, очень много внимания уделяется тестированию конфигураций, т.е. конфигов.
Конечно же у них есть нагрузочное и канареечное тестирование.
Если SR-инженер подключается к проекту на этапе когда он уже реализован, но тестов нет совсем, какие тесты нужно писать? Покрывать все юнитами уже нет смысла и времени.
Чтобы определить что покрывать тестами, нужно ответить на следующие вопросы:
- можно ли каким-то образом выделить наиболее важное место в коде?
- существуют ли куски, которые отвечают за потребительский опыт (например биллинг)?
- есть ли API с которыми будут работать другие команды?
“Передача в эксплуатацию некорректно работающего ПО - это главный смертный грех разработчика”
Инструменты разработанные в SRE так же нуждаются в тестировании как и другие программы.
43
Глава «Разработка ПО службой SRE»
Так как SRE команда состоит в первую очередь из SWE эти ребята еще и код пилят. Чаще всего это внутренние сервисы.
В книге приводится пример с Auxon - системой для планирования производительности (Capacity planning) основанного на целях.
Суть в том, что в гугле устали от запросов «дайте столько-то ядер CPU” или «отсыпьте SSD дисков» и решили перейти к схеме, при которой product owner говорит «хочу чтобы сервис отвечал за 100ms вот в этом регионе». Все требования и лимиты загружаются в Auxon в виде конфигов, а тот выдает план распределения ресурсов.
Пилили они его два года, чтобы в итоге им могли пользоваться разные команды и переход был ненапряжный.
Цель это то, чем владелец сервиса аргументирует запрашиваемые для него параметры функционирования
Но речь вообще не об этом, а о том как и зачем SRE команда в гугле пишет софт. Продолжим в следующий вторник.
44
Для SRE работа над долгосрочными проектами служит противовесом для дежурств и авралов. А также позволяет почувствовать удовлетворение от работы тем инженерам, которые хотели бы заниматься не только проектированием систем но и разработкой ПО.
Как запускать проект в SRE:
- четко сформулируйте задачу и доведите ее до сведения остальных
- оцените возможности вашей организации
- запускайте и дорабатывайте
- не занижайте стандарты
Социализация внутренних программных инструментов для крупной аудитории требует:
- понятного и неизменного подхода
- рекламы среди пользователей
- сотрудничества со стороны инженеров и менеджеров, которым вы будете демонстрировать полезность вашего продукта
Какой проект плохой кандидат?
- он связан с изменением слишком многих частей
- его дизайн требует подход “все или ничего”
- мешает выполнять разработку итерационно
Нельзя обещать слишком много, лучше MVP с постоянными патчами-доработками.
В любом достаточно сложном проекте разработки ПО обычно приходиться иметь дело с неопределенностью.
Просто запускайте свой продукт поскорее и дорабатывайте по ходу.
Проект должен разрабатываться без помех и перерывов. Подразумевается, что инженер, который, в данный момент работает над проектом, не должен участвовать в on-call ротации. Либо это должно быть грамотно распланировано.
45
Естественно что балансировка нагрузки в Google начинается задолго до бэкенд серверов, еще на уровне DNS.
Промежуточные кеширующие DNS серверы сильно мешают балансировать запросы, поэтому Google постоянно мониторят известные промежуточные DNS серверы и размер их пользовательской базы. оценивают географическое расположение пользователей находящихся за каждым промежуточным сервером, чтобы направлять их в ДЦ с лучшим расположением.
Никаких деталей особо не раскрывается, кроме того что используется ipv4 + GRE. Про dns over https и ipv6 вообще ничего не упоминается.
Дальше идет балансировка на уровне фронтенд серверов, которые первым встречают пользовательский запрос, ближайший аналог - haproxy/traefik.
Для разных типов запросов - разное понятие оптимальности распределения.
Так для поисковых запросов выбирается ближайший доступный дата центр определяемый по RTT, чтобы минимизировать latency. А для видео, запрос отправляется на наименее загруженный узел, чтобы достичь максимальной пропускной способности.
После этого начинается балансировка в дата центре, заметки по которой будут в следующий раз.
46
Балансировка в дата центре
Тут переводчики видимо чуть чуть поплыли и термины становятся странными. Короче есть прокси и бэкенды, прокси определяет на какой бэк отправить запрос. Бэкенд может быть в одном из трёх статусов:
- полная работоспособность
- отказ в соединение
- хромая утка - бэкенд может обслуживать запросы, но не хотел бы
Самое интересное тут, что бэкенд сам информирует прокси что он перешел в состояние хромой утки, чтобы они перестали присылать ему новые запросы.
Режим хромой утки также используется при обновлении кода:
- в бэкенд прилетает SIGTERM
- он говорит проксям отправлять новые запросы другим бэкендам
- дорабатывает запросы которые уже пришли
- и завершает работу
Google использует пул соединений между проксями и бэкендами, чтобы избежать проблемы слишком большого количества открытых соединений с одной прокси на бэкенды или с многих прокси на один бэкенд.
При этом у проксей есть ограничение, с каким количеством бэкендов они соединены и держат связь. Бэкенды распределяются по проксям согласно детерминированному алгоритму, для равномерной загрузки.
Если нет активности в течении некоторого времени, происходит переход с постоянного TCP соединения на UDP проверки.
Лучшим алгоритмом распределения пользовательских запросов по бэкендам Google считает Weighted Round Robin
P.S. Из-за кривости написания, я не разобрался в итоге речь про обратные прокси типа Nginx или прям про клиенты (web, mobile). Там то одно то другое. Например иногда говорится что клиент это Java приложение ¯\_[ツ]_/¯. Надо будет обратиться к оригиналу.
47
Напоминаю, что мы говорим про балансировку пользовательских запросов.
Все запросы которые улетают на бэкенд имеют определенный уровень критичности. Один из четырех:
- CRITICAL_PLUS - наиболее критичные
- CRITICAL - стандартный уровень для прода
- SHEDDABLE_PLUS - ожидается частичная недоступность (например крон задачи, которыми можно пренебречь в данный момент, потому что потому они запустятся снова)
- SHEDDABLE - трафик для которого часто ожидается частичная или полная недоступность
В случае перегрузки, бэкенды троттлят запросы на основании этих уровней критичности.
В случае ошибки производится до 3 попыток запроса в бекенд, но процент повторных запросов должен быть не больше 10%.
Собирается статистика по повторам запросов, и бэкенд, если видит что другие бекенды тоже много отбрасывают, может вернуть ошибку “перегружен, не повторять”, вместо “перегружен, попробуйте позже” чтобы снизить нагрузку.
48
Почему нужно предотвращать перегрузку сервисов?
Итак, у нас есть сервис с нагрузкой 10 000 QPS. Сервис полностью работоспособен.
Нагрузка увеличивается до 11 000 QPS и начинается каскадный сбой.
В этом случае, снижение нагрузки до 9 000 QPS, скорее всего, не остановит процесс и чтобы стабилизировать систему, придется снимать нагрузку полностью и потом ступенчато её возобновлять.
Как можно предотвращать перегрузку сервисов?
Можно отбрасывать часть запросов - это называется троттлинг (которые в книге, почему-то, перевели как сегментация)
А можно начать мягкую деградацию. Деградированные результаты - это низкокачественные результаты, но более дешевые для вычисления.
49
В книге разделяются понятия “таймаут” и “дедлайн”, не совсем понял почему так. Лично я привык звать это все таймаутами.
Дедлайном они называют время, до которого какой-либо сервис ждет ответа. Ну, т.е. таймаут 🙂
Из интересного, решил записать про распространение дедлайнов. Их легко объяснить на примере:
Дедлайн на фронте 30 секунд - запрос прилетает в бекенд А и выполняется 7 секунд, после чего бекенд А делает запрос в бекенд Б с дедлайном 23 секунды, бекенд Б выполняет запрос 12 секунд и отправляет запрос в бекенд В с дедлайном 11 секунд и т.д.
Если дедлайны в сервисах будут больше чем дедлайны, которые стоят раньше, то наши бекенды будут делать работу, которая уже ни кому не нужна.
Далее следует глава 23 “Разрешение конфликтов: Консенсус в распределенных системах”
Для меня ничего нового, в главе было очень много про Paxos и пару раз упоминаются Zab и Raft.
При этом в Etcd и Kubernetes используется Raft
Задачи для распределенного консенсуса:
- ситуация выбора лидера
- критическое разделяемое состояние
- распределенные блокировки
Любой другой подход будет напоминать бомбу с часовым механизмом, готовую разрушить ваши системы.
50
Глава “Cron: планирование и расписание в распределенных системах”
Лучше пропустить запуск задачи чем запустить её два раза (например e-mail рассылка или пересчет ЗП)
Владельцы задач должны наблюдать за своими задачами
Хранение информации о состоянии задач:
- во внешнем хранилище (GFS или HDFS)
- внутри сервиса cron
Google выбирает 2 вариант, потому что 1 это большая задержка и зависимость от глобального сервиса.
Несколько реплик сервиса cron достигают консенсуса по Paxos. Только лидер Paxos является лидером cron и может изменять состояние, запускать задачи и уведомлять фоловеров о статусе. Лидер сообщает фоловерам о том, что запустил или завершил задачу синхронно, чтобы избежать повторного запуска при смене лидера.
51
Выполнение cron задачи в гугле это запуск контейнеров в k8s и их убийство, когда задача выполнена.
Т.е. в случае, когда лидер запустил задачи, потом упал или стал недоступен, кто-то из фолловеров становится лидером и должен завершить задачи запущенные предыдущим лидером или дозапустить если тот успел не все.
Успешно запустив задачу, cron планирует время следующего запуска этой задачи.
Paxos это по сути журнал изменений состояния, они хранят его (журнал) на локальном диске, периодически делают снимки и копируют в распределенное хранилище. Новый фолловер может вытянуть данные по сети.
Удостоверьтесь что ваши команды не запланировали задачи cron на запуск в одно и тоже время.
Можно использовать нотацию распределенного запуска (например разработчик указывает что запустить нужно с 23 до 0 часов) а система cron сама решает в какую конкретно минуту какую задачу запустить.
На этом все про Cron задачи, добавлю что, на данный момент, мы в OneTwoTrip используем https://github.com/onetwotrip/shaker.
52
Глава “Конвейеры обработки данных”
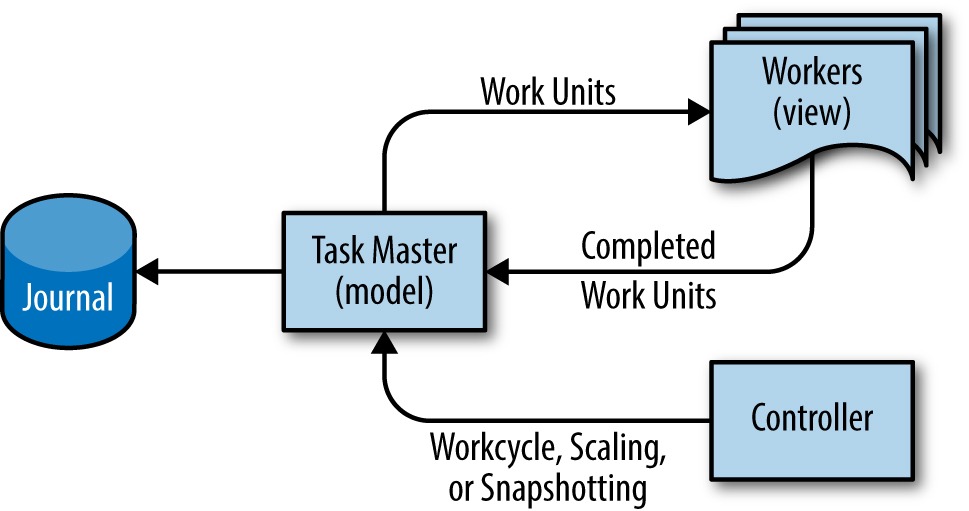
Google Workflow - система позволяющая масштабировать продолжительную обработку данных. Использует шаблон “Лидер - фоловер (или воркер)” и шаблон системного преобладания. Эта комбинация позволяет создавать крупномасштабные транзакционные конвейреы, гарантируя корректность благодаря семантике exactly-once.
Workflow использует MVC
Модель находится на сервере - мастере задач, который держит в памяти состояние всех задач а синхронные изменения сбрасывает на диск.
Представление - это воркеры, которые меняют стейт транзакционно через мастер, но сами его не хранят, поэтому могут быть удалены в любой момент.
Kонтроллер - опциональный компонент, который обеспечивает масштабирование конвейра во время работы, получение снимков, откат состояния и т.д.
53
Воркеры в главе упорно называют работники, что режет мне слух … или глаз
4 гарантии корректности для Workflow:
- результат работы воркеров с помощью конфигурационных задач создает барьеры, на которых основывается работа (что это блин значит!)
- фиксация выполненной работы требует наличия у воркера аренды, действительной в данный момент
- воркеры дают выходным файлам (с результатами работы) уникальные имена (зачем вообще использовать файлы?)
- клиент и сервер проверяют правильность мастера задач путем проверки токена сервера в каждой операции
Непрерывность работы Workflow достигается за счет использования глобальных Workflow, которые управляют локальными Workflow в разных ДЦ, в которых уже выполняются задачи.
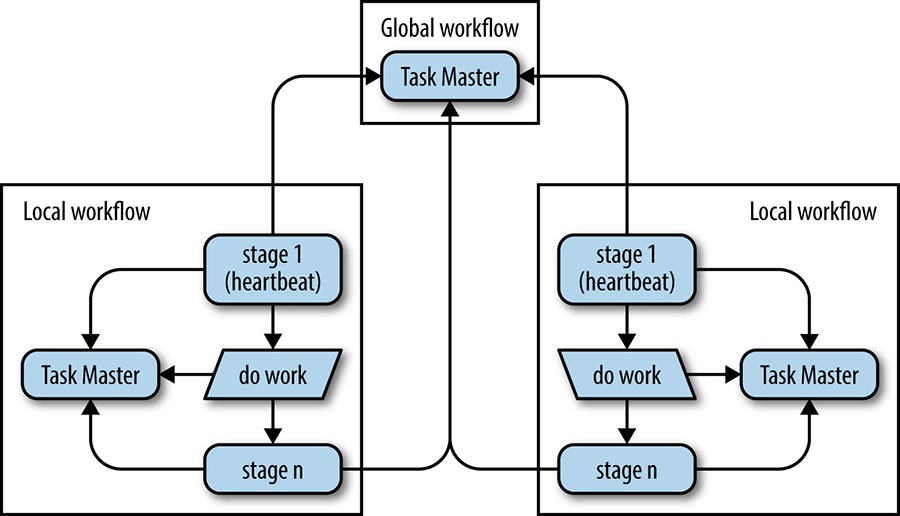
Это самая мутная (непонятная) глава на данный момент. Дальше идет глава про сохранность данных и там интереснее.
54
Глава “Cохранность данных: как пишется так и читается”
Для пользователя доступность сервиса и доступность данных это почти одно и тоже.
Если Gmail открывается, но писем нет, он все равно считает что Gmail не работает.
Допустим файл был поврежден, мы это заметили, исправили его и вернули к исходному состоянию. На все про все, ушло 30 минут. Если это был единственный простой с этим файлом, его доступность за год составит 99,99%.
Но, с точки зрения пользователя, если он не обращался за файлом во время повреждения и восстановления, доступность будет 100%.
Это и есть секрет исключительной сохранности данных - упреждающее обнаружение проблем и быстрое восстановление.
Никто не хочет делать резервные копии, но все хотят восстановления данных.
В случае аварии, данные должны быть быстро восстановлены из резервной копии. В случае если восстановление занимает долгое время это архив а не резервная копия.
Создавать нужно систему восстановления, а не систему резервного копирования.
Должен быть SLO для “сохранности данных” при разных типах неисправностей.
55
24 вида сбоев.
Сбои, которые ведут к потере данных имеют три компонента (наверное любой сбой в принципе имеет такие компоненты):
- Основная причина: действие пользователя, ошибка в работе, ошибка приложения, дефект инфраструктуры, сбой оборудования, авария на площадке
- Масштаб: широкий , узко-направленный
- Уровень: большой взрыв, медленный и постепенный
Репликация не защищает от множества способов потерять данные.
Сохранность - показатель, как долго вы храните копии данных. Если потеря данных постепенная, то заметите вы это не сразу.
Глубокая защита от потери данных в Гугле.
Три слоя:
- Мягкое (ленивое) удаление
- Резервные копии и методы их восстановления
- Проверка данных
56
БОльшая часть случаев хищения учётных записей и проблем с целостностью данных обнаруживаются в течение 60 дней.
Гугл рекомендует срок хранения резервных копий от 30 до 90 дней.
Должно быть несколько слоев создания резервных копий.
Первый - большое количество копий, хранятся максимально близко к работающим хранилищам и с помощью которых можно быстро выполнить восстановление.
На втором и последующих уровнях, снижается количество копий, отдаляется сторадж и увеличивается время восстановления.
Валидаторы данных это конвейеры на базе mapReduce или Hadoop которые пишут сами разработчики сервисов.
Система проверки данных должна предоставлять дежурному инженеру всю необходимую документацию и инструменты поиска проблем.
Если каждая команда будет заниматься реализацией системы проверки данных, они не будут успевать пилить фичи.
Можно выделить специальную инфраструктурную команду, которая разработает фреймворк проверки данных для остальных команд, которые пилят продукты.
Нужно постоянно тестировать восстановление из резервных копий. Важен не только факт восстановления, но и целостность данных а также время восстановления (оно должно быть адекватным) и готовность инфраструктуры.
Алерт на удаление большого количества данных. Например 10х от 95 перцентиля.
57
Глава 27 - надежный масштабируемый выпуск продукта
В гугле постоянно запускаются проекты, какие-то новые с нуля, какие-то новые версии уже существующих, специальные проекты и так далее. Чтобы не наступать на одни и те же грабли из SR-инженеров выделили команду Launch Coordination Engineers - LCE, которые занимаются только запуском проектов.
В течение 3,5 лет один LCE проводил 350 запусков, поскольку команда в среднем из 5 человек это более 1500 запусков.
Чтобы облегчить себе жизнь LCE используют чек-листы (по аналогии с пилотами и хирургами).
- Они проверяют продукты и сервисы на соответствие стандартам надежности гугла, а также дают советы и рекомендации как увеличить надежность.
- Действуют как посредники между несколькими командами, участвующими в запуске
- Управляют техническими аспектами и гарантируют стабильность и надежность запуска
- Обучают разработчиков лучшим приемам и способам интеграции с другими сервисами, обеспечивая документацией и практическими упражнениями
Качества необходимые LCE инженеру:
- широта опыта (внутренних продуктов и пошареных ресурсов)
- кросс-функциональная перспектива
- объективность
58
Критерии определяющие удачный запуск:
- простота для разработчиков
- продуманность - обнаружение очевидных ошибок
- доскональность - решаются наиболее важные проблемы
- масштабируемость - выполняется как большое количество простых запусков так и небольшое сложных
- адаптируемость - процесс налажен для разных видов запусков - добавление новой локали или запуск полностью нового продукта
Чек-лист состоит из пунктов, в каждом есть вопрос и действие. В случае если ответ на вопрос положительный, нужно выполнить действие. Например:
Вопрос: нужно ли вам новое доменное имя?
Действие: поговорите с маркетингом о том, каким должно быть желаемое доменное имя и запросите регистрацию “вот ссылка на форму маркетинга”
Вопрос: сохраняете или вы устойчивые данные?
Действия: реализуйте ограничение скорости и квоты. Используйте следующий разделяемый (shared) сервис.
Размер чек-листа удерживается, чтобы быть адекватным, но может быть изменен для конкретного запуска.
Также, на сколько я понял, в ведомстве LCE находятся “фреймворки” канареечного применения функциональности. Которые позволяют раскатывать новые фичи ступенчато, сначала на малое количество пользователей, потом на большее и так далее.
LCE пока не решили:
- бюрократия
- проблемы масштабируемости после запуска (переписывание инфры проекта с нуля)
- рост операционной нагрузки
- текучка инфраструктуры
59
Вы наняли новых SR-инженеров, что теперь?
В гугле считают что самое важное для новичка - научиться дежурить, а инженерная работа сама приладится.
Для обучения новичка нужно знать ответы на вопросы:
- что он должен знать, чтобы начать дежурить?
- как можно оценить его готовность к дежурству?
- как можно воспользоваться энтузиазмом и любопытством новичков, чтобы принести пользу SRE
- какой вклад существующие инженеры могут внести в обучение новых сотрудников?
Люди разные и ни одна методика обучения не подойдет ко всем новичкам. Поэтому гугл дает “приемы” обучения SR-инженеров. Рекомендованные методы и антиметоды:
Метод: разработка конкретных последовательных упражнений
Антиметод: поручение низкоквалифицированной работы
М: стимулирование к реверс-инжинирингу
А: обучение с помощью операционных процедур, чек-листов и сценариев
М: мотивация к анализу через чтение постмортем
А: сокрытие информации о сбоях
М: создание локализованных, но реалистичных сбоев для обучения системе мониторинга и инструментам
А: предоставление возможности что-то исправить только после заступления на дежурство
М: имитация катастроф, для тренировки работы в команде
А: создание в команде экспертов
М: теневое дежурство (и сравнение их заметок, с заметками дежурного)
А: назначение новичка полноценным дежурным
М: эксперты вместе с новичками проходят план (или его части) обучения
А: рассмотрение планов обучения как неизменных и неприкосновенных для всех кроме экспертов
М: обособление нестандартной работы над проектом для выполнения учениками
А: предоставление всей работы над новыми проектами только самым опытным
60
Постарайтесь упорядочить систему обучения.
Некоторые команды используют специальные пошаговые документы/чек-листы для новичков. В них дается описание сервиса, эксперты и разработчики и список необходимых знаний, например:
- Перед тем как двигаться дальше изучите A, B и C.
- Прочтите и проанализируйте следующий документы …
- Вопросы для самопроверки …
Для качественного обучения полезна целевая, а не черновая работа над проектом.
SR-инженеры должны иметь характерные особенности:
- столкнувшись с системами, которые никогда не видели - знать, как выполнять обратное проектирование (реверс-инжиниринг)
- при работе в больших масштабах будут появляться аномалии, которые трудно обнаружить, поэтому нужна способность мыслить статистически а не процедурно
- когда стандартные решения задач не работают, должны уметь импровизировать
Для тренировки дежурных, гугл использует разные игры, названия некоторых:
Сервис сломался, вся команда пропала в бермудском треугольнике, ты единственный дежурный инженер, что будешь делать?
Реальный сценарий аварии, жертва говорит ведущему чтобы он сделала, а ведущий рассказывает что случится
Давайте сожжем поисковый кластер дотла!
Важным моментом обучения новичка является его переход к самообучению. По сути, это должно быть вершиной обучения.
61
Глава 29 - справляемся с отвлекающими факторами и прерываниями
Состояние когнитивного потока
SR инженер Фред приходит на работу, он не дежурный, делает себе кофе, надевает наушники марки “не беспокоить” и садится работать над своими проектами.
- Прилетает асап тикет
- Коллега дёргает по компоненту, в котором Фред разбирается больше
- Дёргают по тикету, который завели в его прошлое дежурство
- Релиз с кодом Фреда не собирается, надо проверить/поправить/откатить
В итоге Фред не смог сосредоточиться на своих задачах.
20 минутное прерывание это минимум два переключения контекста и потеря нескольких часов действительно продуктивной работы.
Как избежать?
Распределение времени между разными видами работы - концепция потерянного времени (это вольный перевод от Питера в русском варианте книги, советую ознакомиться с оригиналом - http://paulgraham.com/makersschedule.html)
Приходя на работу человек должен знать над чем он сегодня работает. Если человек дежурный, значит он дежурит и не может параллельно заниматься проектной работой.
62
Операционная нагрузка - работа, которую нужно выполнять, чтобы поддерживать систему в функциональном состоянии.
В 30 главе рассказывается, что если у команды SR-инженеров становится много операционной работы, в Google могут прибегнуть к технике, когда в эту команду вводится еще один SR-инженер (в русском переводе этого нет, но я подозреваю, что для этих целей подходит более зрелый SR-инженер, хорошо знакомый с практиками компании).
Этот новый SR-инженер не берется за тикеты и не начинает дежурить, у него есть конкретный план по выявлению причин повышения операционной работы и их устранению.
- Фаза 1: изучаем сервис и рабочее окружение
- Фаза 2: делимся контекстом
- Фаза 3: навязываем изменения
В конце, SR-инженеру, которого временно ввели в команду для улучшения ситуации, нужно написать отчет о проделанной работе и еще несколько месяцев мониторить эту команду, чтобы убедиться, что они практикуют то, чему он их научил.
Про каждую из фаз чуть подробнее в следующих заметках.
63
Фаза 1: изучаем сервис и рабочее окружение:
- знакомимся с командой и задачами
- определяем главные источники стресса
- определяем очаги возгорания:
- пробелы в знаниях
- сервисы разработанные SR-инженерами, важность которых повышается
- игнорирование проблемы из-за веры, что новое решение, которое скоро будет реализовано, устранит все недостатки
- алерты на которые не реагируют ни разработчики, ни SR-инженеры
- SLI/SLO/SLA
- сервис чей план производительности - “добавьте еще серверов, у нас ночью память кончилась”
- постмортемы, которые рекомендуют откат изменений
- любой критически важный компонент, на вопросы о котором SR-инженеры отвечают “мы ничего о нем не знаем, им владеют разработчики”
64
Фаза 2: делимся контекстом
- Напишите для команды хороший, безобвинительный постмортем
- Сортируйте перегрузки в соответствии с их типами
два вида перегрузок:
- одни перегрузки не должны происходить, они вызывают рутину
- другие перегрузки, вызывают стресс и/или приводят к гневной переписке, на самом деле являются частью работы
Разделите перегрузки на рутину и не рутину и предоставьте этот список команде и четко объясните, в каком случае работу нужно автоматизировать, а в каком это допустимая ситуация.
65
Фаза 3: навязываем изменения
Добиться здоровых отношений в команде непросто.
Люди всегда стремятся к поддержанию баланса, поэтому сконцентрируйтесь на создании (или восстановлении) правильных начальных условий или обучите их небольшому набору принципов, необходимых для принятия верных решений.
Начните с основ - SLO.
Не решайте проблемы самостоятельно, найдите для этого члена команды, проговорите с ним как эта работа решает проблему, сделайте ревью его изменений.
Обосновывайте свои аргументы.
Задавайте наводящие вопросы (но не вопросы с подвохом).
66
Глава 31. Общение и взаимодействие в службе SRE
Данные (информация о проектах, состоянии сервисов, систем и отдельных элементов) должны протекать через всю действующую систему, они же должны течь через команду SR-инженеров.
Потенциал службы SRE в том, что она отвечает за надежность имея те же навыки, что и команда разработчиков, что способствует повышению качества.
Специалиста, который отвечает за надежность, но не имеет полного набора навыков, будет недостаточно.
Производственные совещания:
- 1 раз в неделю
- 30-60 минут
- SR-инженеры доносят информацию о состоянии сервиса, за который отвечают
- повестка дня - грядущие изменения
- показатели
- сбои
- события по экстренным алертам
- предыдущие действия
- и т.д.
На совещания могут отправляться один или несколько представителей разработки сервиса.
Формально, команды SR-инженеров, имеют в составе:
- технического лидера - tech lead / TL
- менеджера - manager/SRM
- проектного менеджера - PM/TPM/PgM
Дальше в книге рассказывается две истории:
- как SR-инженеры сначала пилили отдельные фреймворки для мониторинга, а потом объединились и стали разрабывать Viceroy
- как Google Ads переходили с mysql на F1
в обоих историях ничего интересного не нашел
67
Глава 32. Развитие модели вовлеченности SR-инженеров
Вовлечение SR-инженера в проект - PRR - Production Readiness Review
Обычно, на старте, на проект выделяются 1-3 SR-инженера, они начинают с совещания, на котором решают:
- установление SLO/SLA
- планирование изменений в сервисе для повышения надежности
- планирование расписания обучения (освоения сервиса командой SRE)
Чем раньше SR-инженер вовлекается в проект, тем легче потом взять его на поддержку SRE команде и тем надежнее он будет с минимальными затратами.
SR инженеры пилят фреймворки, чтобы разработчики могли сосредоточиться на бизнес логике, а фреймворк заботиться о корректном использовании инфраструктуры.
Структурный подход, основанный на фреймворках сервисов, единой производственной платформе и единой системе управления, дает множество преимуществ:
- Значительно снижена операционная нагрузка
- Универсальная поддержка по умолчанию
- Быстрое вовлечение (SR-инженера) с низкими издержками
- Общая ответственность
Последние две главы совсем вода, больше заметок нет.
#DevOps #TechAndDev