
Обзор
Недавно я провел два воркшопа по внутреннему устройству Kubernetes (k8s), решил сделать текстовую заметку по простой части.
Kubernetes это 5 бинарей
Такую фразу можно часто услышать в DevOps комьюнити, её сарказм в том, что k8s выглядит простым, но на деле является очень сложным продуктом, с большим количеством вариантов запуска и конфигурирования конкретного кластера.
Работу с k8s можно разделить на две части: запуск и поддержка самого кластера/кластеров и работа с кластером в качестве клиента. Мы сейчас больше говорим про первую часть. Потому что прежде чем начать работать с кластером, нужно его запустить и настроить.
Обобщенная схема k8s выглядит примерно так.
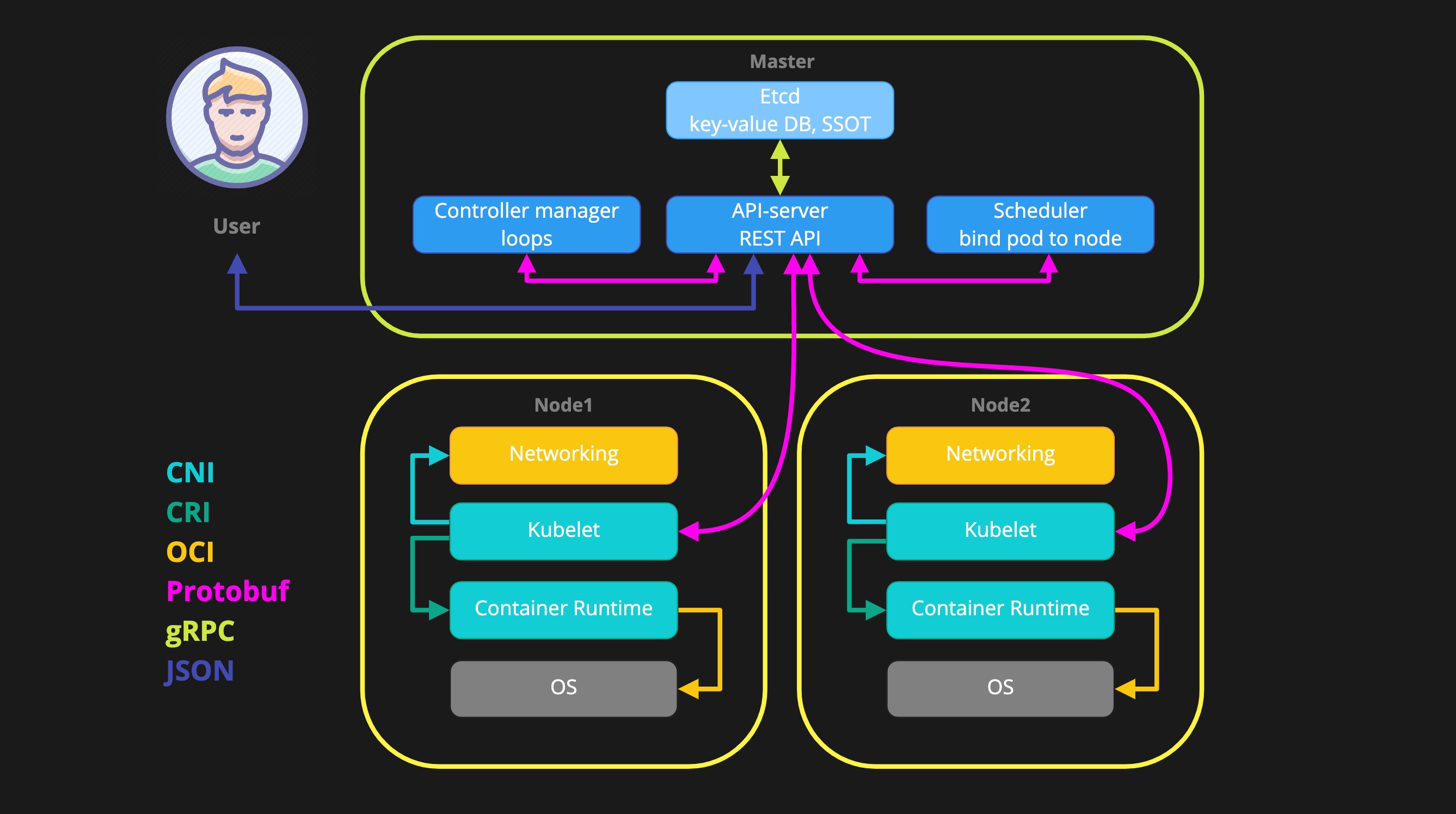
Компоненты делятся на компоненты мастер нод и компоненты воркер нод. К компонентам мастера относятся:
- etcd - key/value база данных, single source of truth
- kube-apiserver - центральный “роутер”, единственный компонент который может писать и читать etcd
- kube-controller-manager - набор лупов, которые периодически просыпаются и обрабатывают конкретные сущности
- kube-scheduler - гранд-мастер тетриса, решает на какой ноде какой под запустить
К компонентам воркер нод, относятся:
- kubelet - связующее звено между apiserver и непосредственно container runtime
- kube-proxy - сетевая прокси, необходимая для работы service
Установка зависимостей
Для начала нам нужно два сервера с linux, я использовал Ubuntu 18.04. Хотя в самом минимальном случае хватит и одного сервера. Перед началом нужно установить все зависимости.
Docker
установим необходимые пакеты
apt update && apt install --no-install-recommends -y apt-transport-https ca-certificates curl gnupg-agent software-properties-common screen jqтеперь добавим gpg ключ APT репозитория docker в нашу систему
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add -ну и добавим сам репозиторий:
add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"теперь можем установить собственно докер
apt update && apt install docker-ce docker-ce-cli containerd.iodocker является container runtime и должен быть установлен на всех серверах, которые мы хотим использовать в качестве worker node
Etcd
Установка Etcd одна из самых простых, из компонентов, необходимых нам. Cкачиваем последний доступный релиз с github
curl -L https://github.com/etcd-io/etcd/releases/download/v3.3.18/etcd-v3.3.18-linux-amd64.tar.gz -o etcd-v3.3.18-linux-amd64.tar.gzсоздаем временную папку
mkdir /tmp/etcd-downloadразархивируем релиз во временную папку
tar -xvzf etcd-v3.3.18-linux-amd64.tar.gz -C /tmp/etcd-download --strip-components=1переносим исполняемый файл etcd в каталог исполняемых файлов
mv /tmp/etcd-download/etcd /usr/local/bin/удаляем временную папку
rm -r /tmp/etcd-downloadKubernetes
Теперь нам осталось только скачать исполняемые файлы Kubernetes, cкачиваем архив с релизом
curl -LO 'https://dl.k8s.io/v1.16.0/kubernetes.tar.gz'разархивируем его
tar -xvzf kubernetes.tar.gzпереходим в папку с файлами и выполняем скрипт, который достанет нам клиентский исполняемый файл - kubectl
cd kubernetes
echo "y" | cluster/get-kube-binaries.shтеперь разархивируем серверные компоненты
cd ..
tar -xvzf kubernetes/server/kubernetes-server-linux-amd64.tar.gzтак же как и с Etcd, перенесем все наши исполняемый файлы в общесистемный каталог, чтобы они заработали
mv kubernetes/client/bin/kubectl /usr/local/bin/
for bin in kube-apiserver kube-controller-manager kube-scheduler kubelet kube-proxy; do mv kubernetes/server/bin/$bin /usr/local/bin/; donekubelet и kube-proxy также нужно скопировать на все серверы, которые мы хотим использовать в качестве worker node
теперь у нас есть все необходимые и мы можем приступить.
Собираем кластер
Будем запускать все компоненты в foreground, поэтому я использую разные вкладки в терминале, но с таким же успехом можно использовать screen.
Docker
для начала убедимся, что docker запущен
systemctl status dockerесли статус не running, то запустим его
systemctl start dockerEtcd
теперь, вспоминаем схему компонентов k8s, единственным источником правды и хранилищем является Etcd, без него ничего работать не будет, запустим его
etcdApiserver
Ну а единственным, кто может общаться с Etcd является apiserver, запустим и его
kube-apiserverупс, ошибочка, apiserver должен знать где Etcd, поэтому используем флаг –etcd-servers
kube-apiserver --etcd-servers=http://127.0.0.1:2379теперь, попробуем выполнить команду
kubectl create deployment web --image=nginxесли сделали все правильно, мы должны увидеть что-то вроде
deployment createdController-manager
Но нас интересует не deployment, а запущенный контейнер, чтобы этого добиться, запустим controller-manager, который создаст replicaSet и pods для нас
kube-controller-managercontroller-manager тоже не желает запускаться просто так и ему нужно указать где apiserver
kube-controller-manager --master=http://127.0.0.1:8080и вроде бы все неплохо, но если в читаться в логи controller-manager, мы увидим ошибку, говорящую что-то про service account и tokens, у нас нет времени с этим разбираться, поэтому просто выполним
kubectl edit sa defaultи добавим в открывшийся файл в конец, с начала строки:
automountServiceAccountToken: falseошибки в controller-manager должны уйти, но на всякий случай мы можем остановить его (ctrl+C) и запустить заново
мы можем посмотреть состояние в нашем кластере с помощью команды
kubectl get allScheduler
Cледующим компонентом мы запустим scheduler, ему также нужно знать где apiserver
kube-scheduler --master=http://127.0.0.1:8080но подождите, scheduler может назначить pod на какой-нибудь сервер, только если он у нас есть, чтобы проверить это выполним
kubectl get nodesKubelet
У нас сейчас нет ни одной ноды, потому что мы не запустили kubelet, сделаем это командой
kubeletи если вам покажется что все заработало, не обольщайтесь, если запустить kubelet без параметров, он запустится в standalone режиме, т.е. не будет подключен ни к какому кластеру а это не наш случай, остановим его и попробуем передать ему apiserver как с другими компонентами
kubelet --master=http://127.0.0.1:8080упс, так не работает, kubelet воспринимает только конфиг в файле, чтобы сгенерить его используем команды
ls ~/.kube
kubectl config set-cluster local --server=http://127.0.0.1:8080
kubectl config set-context local --cluster=local
kubectl config use-context local
cat ~/.kube/configтаким образом мы получим конфиг по умолчанию, указывающий на то, что apiserver работает на 127.0.0.1 на порту 8080, чтобы использовать этот конфиг запустим kubelet c параметром –kubeconfig
kubelet --kubeconfig ~/.kube/configтеперь, команда kubectl get nodes, должна возвращать нашу ноду в статусе Ready, а спустя некоторое время, наш pod должен перейти в статус running
Kube-proxy
мы даже можем попробовать обратиться в наш pod, для этого создадим service
kubectl expose deployment web --port=80теперь посмотрим какой ip адрес был выдан нашему service
kubectl get svcдопустим это адрес 10.0.0.241, попробуем выполнить curl на него
curl 10.0.0.241этот запрос не выполнится, можете не ждать. Для того, чтобы service заработал, нужно запустить kube-proxy, в новой вкладке выполним
kube-proxy --master=http://127.0.0.1:8080теперь повторим наш curl, он должен выполниться и мы получим html страницы по умолчанию веб-сервера nginx
curl 10.0.0.241если вы дошли до этого шага, это уже можно считать успехом. Но если у вас есть второй сервер, можем попробовать добавить его как вторую worker node.
Добавление второй ноды
Для этого скопируем наш конфиг на второй сервер
cat ~/.kube/config
vim kubeconfigи внесем в него исправление, вместо 127.0.0.1 нам нужно использовать IP адрес нашего первого сервера, его можно найти используя команду ifconfig или ip.
ip -c aпопробуем запустить наш kubelet на втором сервере командой
kubelet --kubeconfig kubeconfigи тут мы столкнемся с ошибкой, потому что apiserver запущен на локальном интерфейсе 127.0.0.1. Давайте вернемся во вкладку на первом сервере в которой запущен apiserver, остановим его и запустим снова но уже командой
kube-apiserver --etcd-servers=http://127.0.0.1:2379 --address=0.0.0.0при этом controller-manager и scheduler автоматически остановятся, запустим их заново
kube-controller-manager --master=http://127.0.0.1:8080
kube-scheduler --master=http://127.0.0.1:8080снова попробуем запустить kubelet на втором сервере
kubelet --kubeconfig kubeconfigтеперь команда kubectl get nodes должна возвращать оба сервера в статусе Ready, ну и чтобы проверить что pods запускаются на обоих серверах, запустим простой сервис
kubectl create deploy httpenv --image=jpetazzo/httpenv
kubectl scale deploy httpenv --replicas=3 # количество реплик можно выбрать любое, главное больше 2ух
kubectl expose deploy httpenv --port=8888посмотрим на каких нодах запустились pods командой
kubectl get pods -o widepods должны быть распределены по нодам примерно одинаково. Посмотрим какой IP адрес получил наш service
kubectl get svcдопустим это 10.0.0.74, попробуем обратиться на него через curl
while sleep 0.3; do curl -s 10.0.0.74:8888 | jq .HOSTNAME; doneмы должны получать ответы от подов запущенных на той же ноде, на которой выполняется команда curl, но не будем получать ответ от подов запущенных на другой ноде, дело в том, что сети наших kubelet изолированы друг от друга, но это уже тема следующего воркшопа.
#DevOps #Kubernetes #TechAndDevЕсли у вас есть вопросы, предложения или вы нашли ошибку, можете смело писать мне в Twitter или на почту (ссылки слева под аватаркой).